Hadoop MapReduce 源于 Google 在2004年12月份发表的 MapReduce 论文。Hadoop MapReduce 其实就是 Google MapReduce 的一个克隆版本
MapReduce 入门
MapReduce是一种编程模型,其思想来自于函数式编程,和Python,Lisp语言中的map和reduce函数类似,用于大规模数据集的分布式运算
python map函数
1 | >>>def square(x) : # 计算平方数 |
1 | >>>def add(x, y) : # 两数相加 |
MapReduce进阶
MapReduce工作过程
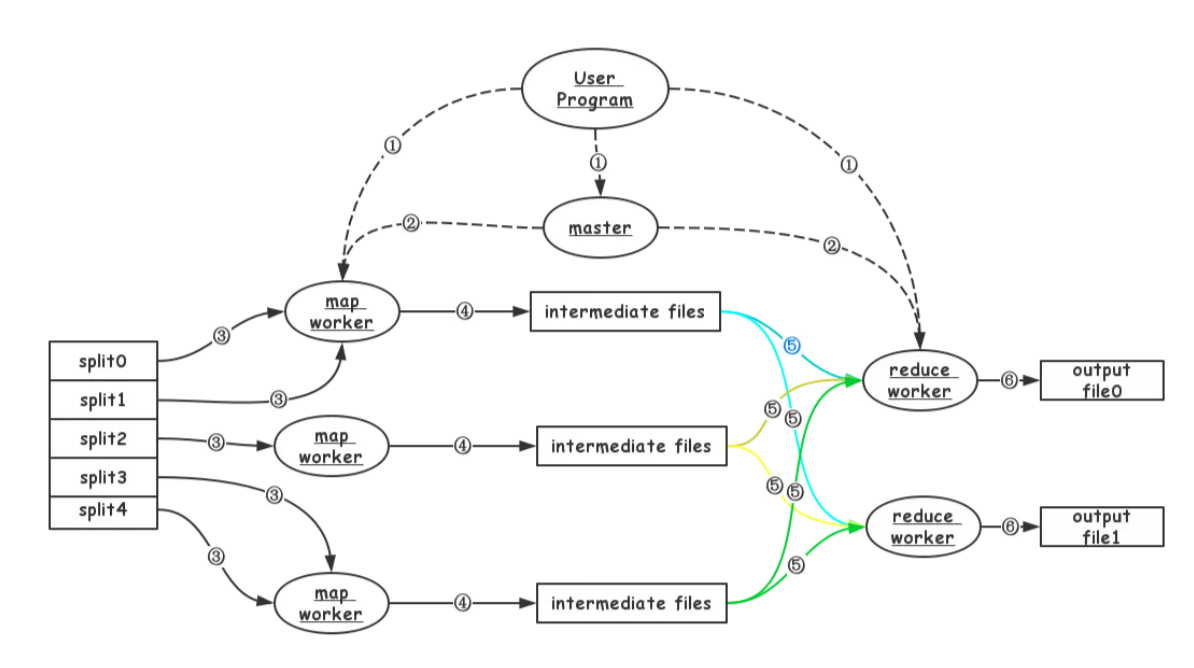
- MapReduce框架对输入的文件数据分成M片,每份数据的大小为16~64MB(可由用户配置)。
- 在多台机器上开始运行User Program:包括一个master、多个map worker和多个reduce worker。
- master主要负责map worker和reduce worker的状态管理和任务分发。
- map worker从GFS读取分配到的文件数据,并进行相应的处理。MapReduce框架的调度会尽量使map worker运行的机器与数据靠近,以提高数据传输的效率。所以,数据传输可以是本地,也可能是网络。
- map worker的输出缓存在内存中,并定期刷到本地磁盘上。这些中间数据的位置信息会通过心跳信息告诉master,master记下这些信息后,通知reduce worker。数据存储在本地。
- reduce worker通过RPC从map worker读取需要的中间数据。数据通过网络传输。
- reduce worker对中间数据进行“合并”处理后,输出结果。
容灾
MapReduce 如何容灾是其最重要的部分,对于故障我们可以分为 worker故障和master故障,worker故障又可以分为 map worker和reduce worker。
Worker故障
Master 通过心跳的机制来检测worker故障
- map worker
- map任务执行完成后宕机:因为中间数据存储在本地磁盘,需要重新执行。
- map任务执行完成前宕机:需要重新执行
- reduce worker
- reduce任务执行完成后宕机:因为数据存储在GFS,不需要重新执行
- reduce任务执行完成前宕机:需要重新执行,输出文件可以覆盖原来的(文件名一样)
Master故障
master宕机,任务失败,可以简单的通过周期写快照的方式来处理master故障
优化
- 局部性:MapReduce用于大数据集的处理,其主要瓶颈是网络带宽。通过优化调度,可以让执行MapReduce任务的机器尽可能靠近机器。(同一机器==>同一机架==>同一机房…)
- 任务粒度:执行MapReduce任务的过程其实就是M个Map任务+R个Reduce任务。M和R必须比机器数大很多才会有利于负载均衡
- 备份任务:当MapReduce任务即将执行完成时,MapReduce框架会针对那些还在执行的任务,启动一个对应的备份任务。之后,只要主任务或备份任务执行完成,MapReduce任务就完成了。这样可以有效避免整个MapReduce任务被少部分比较慢的机器拖死
mapReduce试用范围
- 要想使用mapreduce首先要确保输入可以相对独立的进行计算(map),数据之间没有计算依赖关系
疑问
一个mapreduce中,reduce是否需要等待所有mapper执行后才执行?
需要,在 mapper 结束之前,reducer 很难知道属于一个 key 的数据是否收集完整,因此如果过早地开始 reduce,无法保值结果的正确性如果一个mapper执行特别慢会拖慢整个任务(长尾现象)
为了应对长尾现象(一个特别慢的子任务拖慢整个任务),MapReduce提供了 Backup Task的机制:当一个MapReduce接近结束时,master 对还处理 in-progress状态的task额外的调度备份执行,当primary和backup中一个执行成功就标记成功。Mapreduce中Map与Reduce任务的个数如何确定
Mapreduce中Map与Reduce任务的个数
参考
Google-MapReduce中文版
Google-MapReduc
论文笔记:MapReduce
MapReduce论文笔记
MapReduce之Shuffle过程详述
https://blog.csdn.net/zhanglh046/article/details/78360762
https://github.com/feixiao/Distributed-Systems